语音识别从入门到放弃
语音识别是将语音信号转换为文字。语音识别应用广泛,如智能音箱,语音搜索,语音交互等。语音识别技术的研究已经超过半个世纪,从简单的语音片段匹配,孤立词的识别到基于统计模型和概率的HMM-GMM以及连续语音识别,目前已经发展到了用深度学习构建端到端的语音识别系统。
本文只是对使用Kaldi做语音识别的作业进行一个总结,并不会涉及太多原理的(我也不懂)。本文很多内容直接参考或借鉴了很多网上的资料,相当于做了一个整合,最后结合一个kaldi实践例子。
语言由单词word组成,单词由音素phone组成 。语音变成文字的大致流程为:将一段语音的声波按帧切开,用帧组成状态,用状态组成音素,再将音素合成单词,语音就变成了文字 。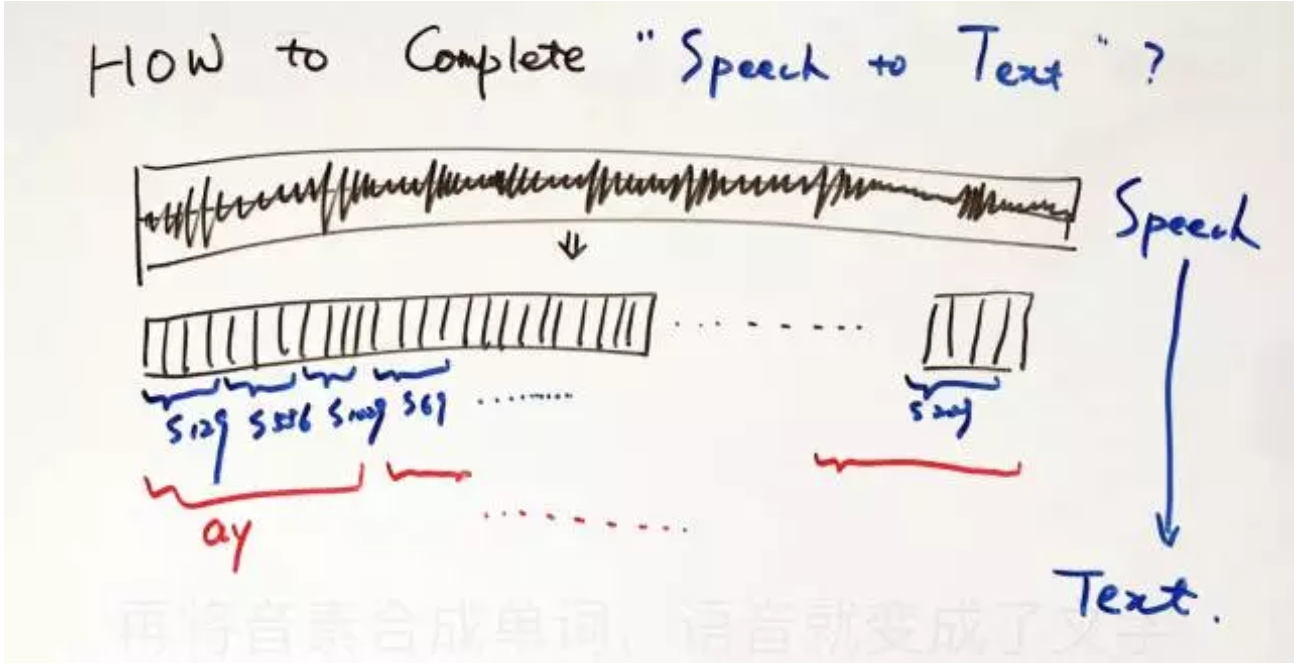
典型的语音识别系统组成
如下图所示,做一个完整的语音识别系统一般由前后端两大模块组成。
- 特征提取负责将从语音信号中提取特征,用于建立识别模型
- 声学模型负责在语音特征和音素之间建立映射,将语音转化为音素
- 语言模型用于判断什么样的句子「像话」,什么样的句子「不像话」
- 解码器用于在海量的句子中快速找到比较好的识别结果
参考资料:如何入门语音识别? - 知乎
下面部分将对每个模块进行介绍。
语音特征提取
语音信号是连续不断的值,无法直接用于建模,当然现在火热的DNN模型已经不需要提取特征啥的。MFCC特征(梅尔频率倒谱系数)是一种在自动语音和说话人识别中广泛使用的特征。主要提取流程如下: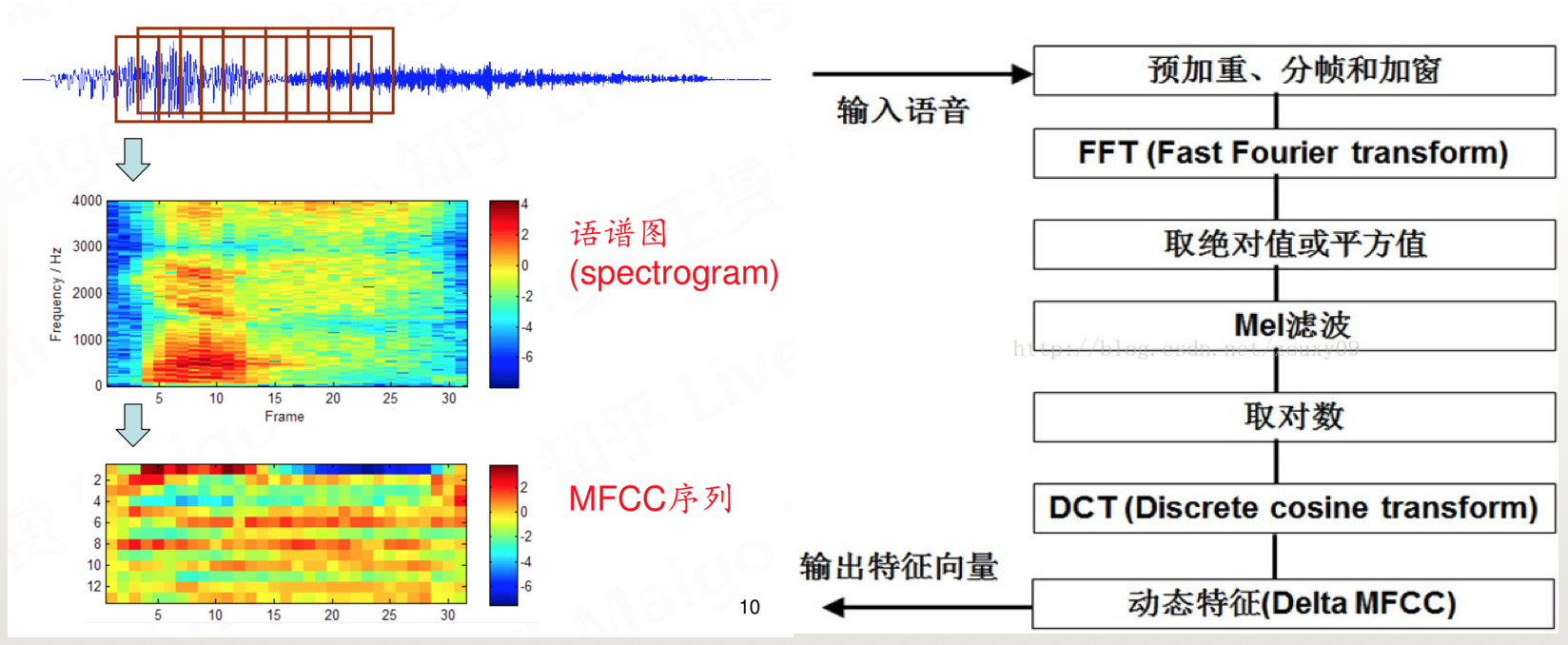
- 对语音进行预加重、分帧和加窗;(加强语音信号性能(信噪比,处理精度等)的一些预处理)
- 对每一个短时分析窗,通过快速傅里叶变化FFT得到对应的频谱;(获得分布在时间轴上不同时间窗内的频谱)
- 将上面的频谱通过Mel滤波器组得到Mel频谱;(通过Mel频谱,将线形的自然频谱转换为体现人类听觉特性的Mel频谱)
- 在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC,这个MFCC就是这帧语音的特征;(倒谱分析,获得MFCC作为语音特征)
最终语音就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。当日还有FilterBank(fbank)也是一种提取特征的方法,没有做过log和DCT的就是fbank特征。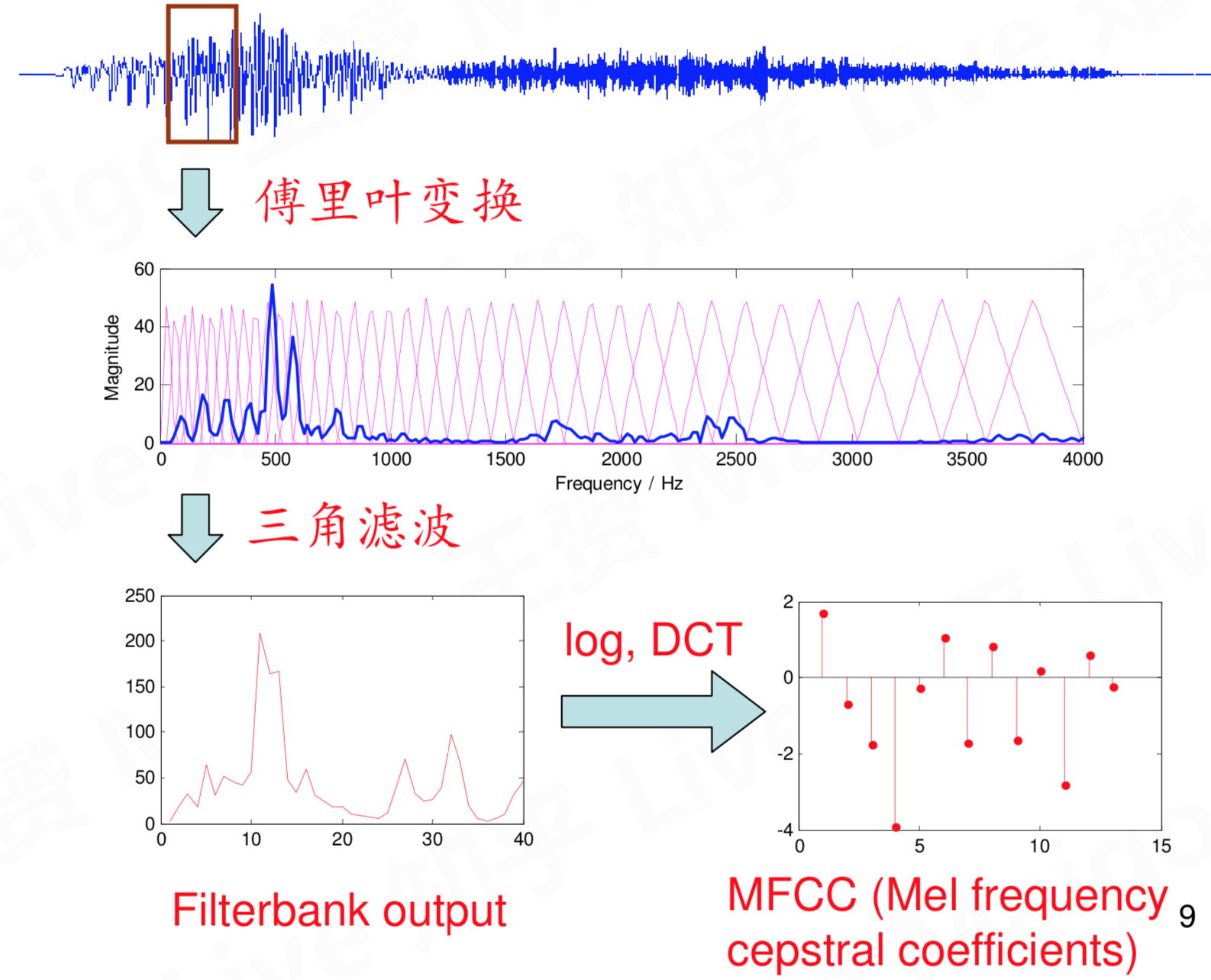
参考资料
梅尔频率倒谱系数(MFCC) 学习笔记 - BaroC - 博客园
MFCC Guide Practical Cryptography
MFCC Python实现 https://github.com/jameslyons/python_speech_features
HMM-GMM
语音识别中,标注只是针对整段音频的,而不是针对每一帧;语音识别是针对每个音素都建立一个HMM模型,而不是所有音素用一个HMM模型描述。
- 字级别的标注
- 音素级别的标注,音素级别的标注工作量很大,可以通过发音词典,将字级别的标注转换成音素级别的标注,这种转换没办法消除多音字的影响,但实际上不会对结果产生太大影响
以“你好,ni hao”为例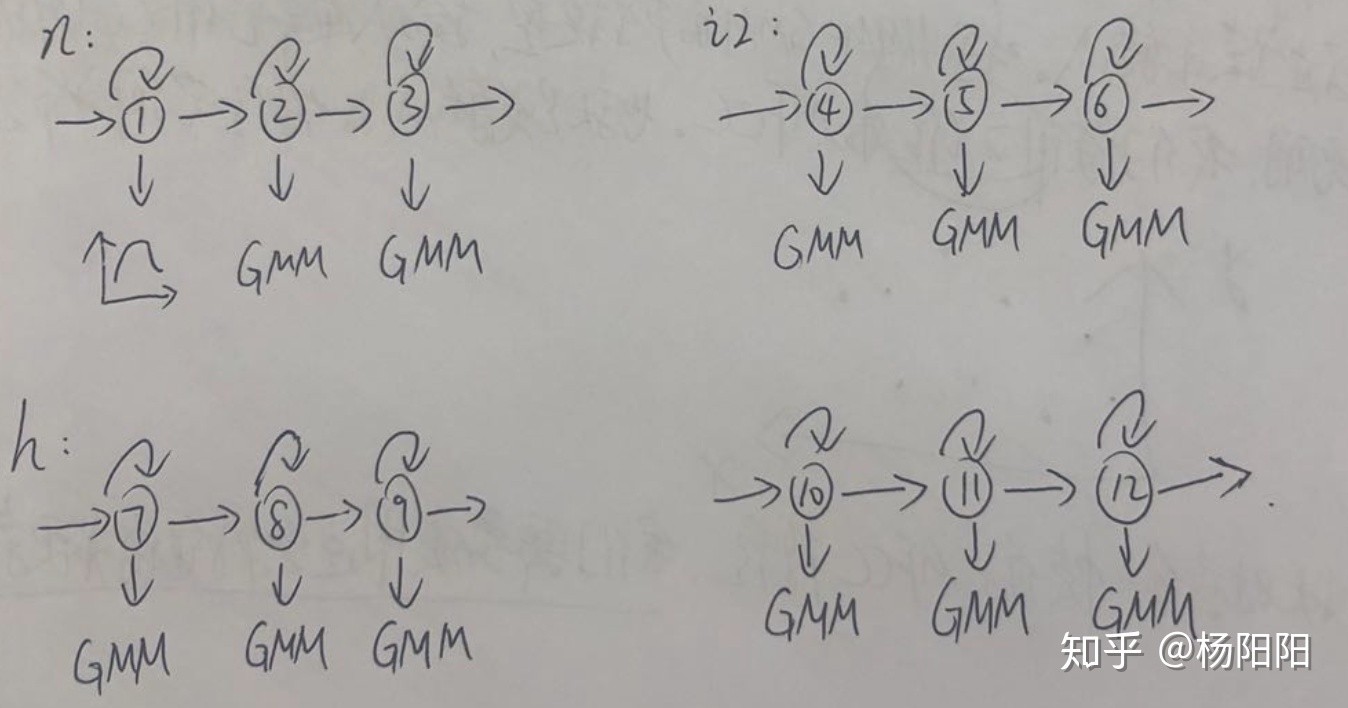
对”n“、”i2“、”h“、”ao3“对应的HMM-GMM模型进行训练,得到模型参数,自环可以对任意长的音频建模,这也是连续语音识别的基础。 - HMM-GMM模型的参数(转移概率、高斯分布的均值、方差)
- 转移概率
- 发射概率:因为我们使用GMM对发射概率建模,所以实际参数就是高斯分布中的均值和方差
- 模型的输入: 每帧信号的MFCC特征(也可以是fbank,plp等),通常取39维的MFCC特征
- 模型的输出:每一帧属于”n”、”i2”、”h”、”ao3”中的某一个状态
HMM-GMM模型的学习过程并不是”有监督的“,音频只告诉我们对应的标注是”n”、”i2”、”h”、”ao3”,并没有告诉我们每一帧(即每一个输入)对应的label是啥。对于这种无监督的任务,我们EM算法来进行训练。
训练步骤:
- 初始化对齐。以上面的20秒音频为例,因为我们不知道每一帧对应哪个声韵母的某个状态,所以就均分。以上面的20秒音频为例,因为我们不知道每一帧对应哪个声韵母的某个状态,所以就均分。也就是说1-5帧对应”n”,6-10帧对应”i2”,11-15帧对应”h”,16-20帧对应”ao3”。同时”n”又有三个状态,那么就把1-2帧分给状态①,3-4帧分给状态②,第5帧分给状态③。”i2”、”h”、”ao3”亦如此。

- 更新模型参数
- 转移概率:通过上图,我们可以得到①->①的转移次数,①->②的转移次数等等。然后除以总的转移次数,就可以得到每种转移的概率,这是一个统计的过程
- 发射概率:即均值和方差。以状态①的均值和方差为例,由上图我们可以知道第1帧和第2帧对应状态①。假设第1帧的MFCC特征是(4,3),第2帧的MFCC特征的MFCC特征是(4,7)。那么状态①的均值就是(4,5),方差是(0,8)
- step3:重新对齐。根据step2得到的参数,重新对音频进行状态级别的对齐。这一步区别于step1的初始化,step1的初始化我们是采用粗暴的均匀对齐,而这一步的对齐是根据step2的参数进行对齐的。这里的对齐方法有两种:a、硬对齐:采用维特比算法;b、软对齐:采用前后向算法

- 重复step2和step3多次,直到收敛。
参考材料:语音识别中的HMM-GMM模型:从一段语音说起 - 知乎
如何评估语音识别的准确率
字错误率WER(WordError Rate),WER=(I+D+S)/N,其中I代表被插入的单词个数,D代表被删除的单词个数,S代表被替换的单词个数。也就是说把识别出来的结果中,多认的,少认的,认错的全都加起来,除以总单词数。
1 | %WER 0.00 [ 0 / 232, 0 ins, 0 del, 0 sub ] |

有了前面的一些基础知识就可以进入实践踩坑环节。
使用kaldi+thchs30进行实践
Kaldi ASR是一个使用广泛的语言识别工具,能够快速帮助初学者建立起一个可用的语言识别系统。入门难度还是挺大,涉及到shell,C++,Python,Perl以及众多的让人眼花缭乱的脚本,很容易让人放弃,做完这个作业我就打算放弃了。如何安装编译kaldi参考源码目录下的INSTALL文件,我在ubuntu18.04上安装的,遇到的问题基本都是系统库没有。
THCHS30 http://www.openslr.org/18/ , 清华大学开源的免费的中文语音识别数据,数据集划分如下:
下面先对kaldi的egs目录下的thchs30中的脚本进行熟悉,然后才能开始干活。
thchs30处理脚本解析
用kaldi做模型基本都遵循同样的套路,run.sh这个文件包含了数据预处理,特征提取,模型建立的流程,理解了这个文件后面就好办了,下面主要对其中的关键部分进行说明。
数据预处理
生成word.txt(词序列),phone.txt(音素序列),text(与word.txt相同),wav.scp(语音),utt2pk(句子与说话人的映射),spk2utt(说话人与句子的映射)
1 | local/thchs-30_data_prep.sh $H $thchs/data_thchs30 || exit 1; |
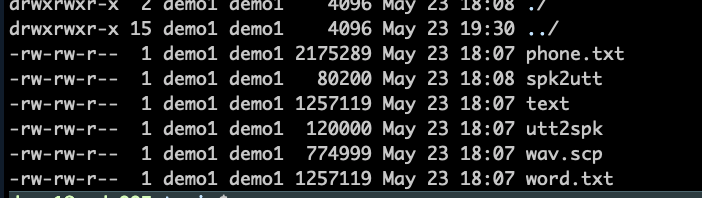
- word.txt:音频标注的文本

- wav.scp:对应说话人和音频的地址

- phone.txt:对应标注的音素序列

- spk2utt:说话人和其音频对应关系,如C32这个人,后面是他声音的音频 , utt2spk则是音频和说话人的对应

特征提取
- 重建data/mfcc目录,然后将train,dev,test,test_phone拷贝到该目录下
- 分别提取 train dev test 的MFCC特征,并进行均值和归一化cmvn(不是必须)
1
2
3
4
5
6
7
8
9
10
11#produce MFCC features
rm -rf data/mfcc && mkdir -p data/mfcc && cp -R data/{train,dev,test,test_phone} data/mfcc || exit 1;
for x in train dev test; do
#make mfcc
# data/mfcc/$x exp/make_mfcc/$x mfcc/$x 分别表示数据目录,日志目录,最终提取的特征目录
steps/make_mfcc.sh --nj $n --cmd "$train_cmd" data/mfcc/$x exp/make_mfcc/$x mfcc/$x || exit 1;
#compute cmvn
steps/compute_cmvn_stats.sh data/mfcc/$x exp/mfcc_cmvn/$x mfcc/$x || exit 1;
done
#copy feats and cmvn to test.ph, avoid duplicated mfcc & cmvn
cp data/mfcc/test/feats.scp data/mfcc/test_phone && cp data/mfcc/test/cmvn.scp data/mfcc/test_phone || exit 1;
词典构建
这一块主要用于语言模型和语音解码,thchs30数据已经提取建好,主要包括3-gram的语言模型,和word-id之间的映射。
词语言模型
1
2
3
4
5
6
7
8
9
10
11
12#prepare language stuff
#build a large lexicon that invovles words in both the training and decoding.
(
echo "make word graph ..."
cd $H; mkdir -p data/{dict,lang,graph} && \
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict && \
cat $thchs/resource/dict/lexicon.txt $thchs/data_thchs30/lm_word/lexicon.txt | \
grep -v '<s>' | grep -v '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
utils/prepare_lang.sh --position_dependent_phones false data/dict "<SPOKEN_NOISE>" data/local/lang data/lang || exit 1;
gzip -c $thchs/data_thchs30/lm_word/word.3gram.lm > data/graph/word.3gram.lm.gz || exit 1;
utils/format_lm.sh data/lang data/graph/word.3gram.lm.gz $thchs/data_thchs30/lm_word/lexicon.txt data/graph/lang || exit 1;
)音素语言模型
1
2
3
4
5
6
7
8
9
10
11
12#make_phone_graph
(
echo "make phone graph ..."
cd $H; mkdir -p data/{dict_phone,graph_phone,lang_phone} && \
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict_phone && \
cat $thchs/data_thchs30/lm_phone/lexicon.txt | grep -v '<eps>' | sort -u > data/dict_phone/lexicon.txt && \
echo "<SPOKEN_NOISE> sil " >> data/dict_phone/lexicon.txt || exit 1;
utils/prepare_lang.sh --position_dependent_phones false data/dict_phone "<SPOKEN_NOISE>" data/local/lang_phone data/lang_phone || exit 1;
gzip -c $thchs/data_thchs30/lm_phone/phone.3gram.lm > data/graph_phone/phone.3gram.lm.gz || exit 1;
utils/format_lm.sh data/lang_phone data/graph_phone/phone.3gram.lm.gz $thchs/data_thchs30/lm_phone/lexicon.txt \
data/graph_phone/lang || exit 1;
)
模型训练(单因素(monophone)->三音素(tri)->LDA/MLLT->SAT->NN)
我这只举monophone例子,后面都是一样,建议不要改动模型训练的顺序,前后有依赖。运行一次,全部训练完就行。
monophone用来训练单音子隐马尔科夫模型,一共进行40次迭代,每两次迭代进行一次对齐操作
1 | steps/train_mono.sh --boost-silence 1.25 --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/mono || exit 1; |
训练之后会有测试,给出模型的字错误率WER。直接run.sh就可以去睡觉了,等待脚本运行完成。
如何查看模型的WER错误率,可以到模型的目录下比如exp/mono/decode_test_phone/scoring_kaldi有个best_wer文件,里面记录了%WER 32.49 [ 117586 / 361864, 16304 ins, 28325 del, 72957 sub ] exp/mono/decode_test_phone/wer_7_1.0
训练后的模型如何使用
这里参考Kaldi初体验(二):thchs30运行 - 他说
- 从
egs/voxforge把online_demo文件夹拷贝到 thchs30 下,和s5同级 - 在online_demo建online-data和work两个文件夹。online-data下建audio和models,models建tri1,audio放要识别的wav,可以自己放几个wav音频文件进去。
- 将s5下
exp/tri1下的final.mdl和35.mdl拷贝到models目录下,把s5的exp/tri1/graph_word里面的words.txt和HCLG.fst也拷过去。其中,final.mdl是训练出来的模型,words.txt是字典,和HCLG.fst是有限状态机。 - 将
online-data/run.sh中的ac_model_type=tri2b_mmi改为ac_model_type=tri1 - 再做如下修改,其实就是将
$ac_model/final.mdl改成了$ac_model/final.mdl
1 | online-wav-gmm-decode-faster --verbose=1 --rt-min=0.8 --rt-max=0.85\ |
之后直接运行run.sh就行,输出如下。暂时不知道WER咋会出现计算错误的问题。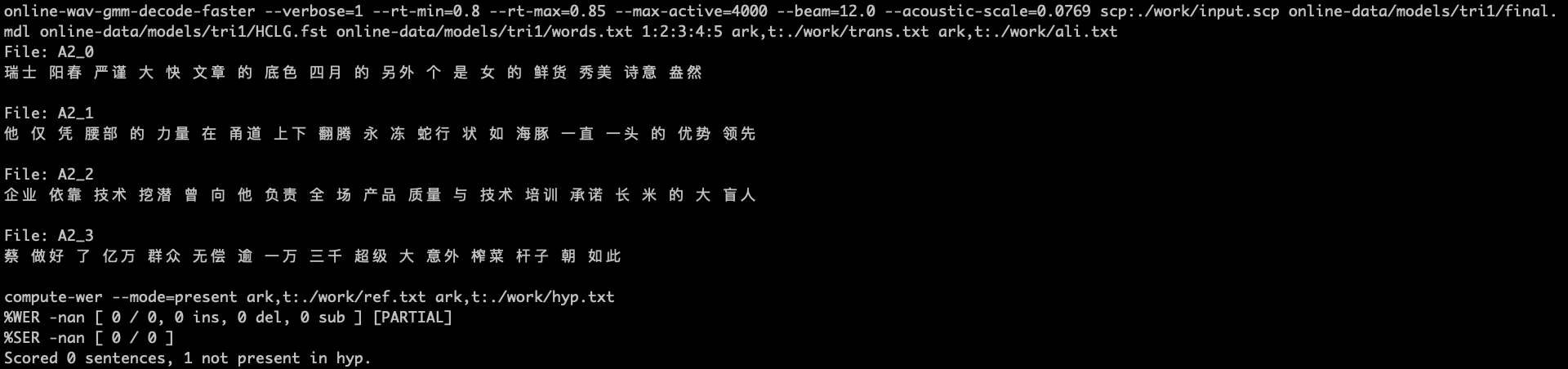
对于其他的模型使用大同小异,比如对于tri2b模型,除了上面那些文件外,还需要拷贝12.mat过去,然后修改两处地方。这里参考基于kaldi的在线中文识别,online的操作介绍 - 人工智能 - CSDN博客
1 | #if [ -s $ac_model/matrix ]; then |
识别结果如下:
识别的准确率还是挺不高的,语音识别技术还是任重而道远,我就不掺和了。
遗留问题:如何使用训练出来DNN模型?
暂时没有解决,Kaldi的工具实在是太多了,复杂而不好用。
如何在线解码(online)
online虽已经废弃,但实在好用,因此还是选择使用online模块进行在线解码。这里参考kaldi - Online Audio Server(服務器客戶端建立方法-舊版在線解碼) - 台部落
这里主要采用online-audio-server-decode-faster进行在线解码,
server端:创建run_server.sh,然后copy下面代码进去,然后运行起来。
1 | KALDI_ROOT=`pwd`/../../.. |
注意:这里有个word_boundary.int 文件需要自己生成。将run.sh中的下面一行改一下,然后单独运行一下这个命令就行。
1 | #原指令: |
client端:创建run_client.sh,然后copy下面代码进去,路径啥的自己解决。
1 | KALDI_ROOT=`pwd`/../../.. |
这里面的example.scp是自己造的,可以在测试集上cp一些数据过来,格式如下:
1 | D32_990 /home/demo1/asr/kaldi/egs/thchs30/data/data_thchs30/test/D32_990.wav |
运行run_client.sh就可以看见实时解码的输出了。
一个问题:如何利用Kaldi构建可以供外部调用的API接口?
这是个麻烦的问题,我目前没有解决,想到的一个好的办法就是重写一下client端,使其支持远程调用。还是得吐槽kaldi的难用,不如自己从头用Python写一个。
其它知识:openfst
语音识别学习记录 kaldi中的openfst - emmmmmm - CSDN博客
总结
代码踩坑的问题就不总结了,主要总结一下我在探索kaldi时遇到的一些方法论上的问题。
- 对语音识别调研不充分,没有形成一个全局的认识就开始搞kaldi,搞了一周后就懵逼了。然后才花了一些时间来重新认识语音识别,了解大致的过程,用到的技术等,这样才避免了被kaldi那繁多的脚本和生成的文件搞乱。做事的顺序不能颠倒了,方法不能错误。进入一个新的领域,没有正确的学习方法会绕很多路。
- 目标不明确,导致多走弯路,过分沉迷于测试不同的代码,想找到适合的那个,却忘了什么才是适合。这就像是走到了多个岔路口,每个都去试下,却忘记看岔路口上的标志。