文本分类的一些总结
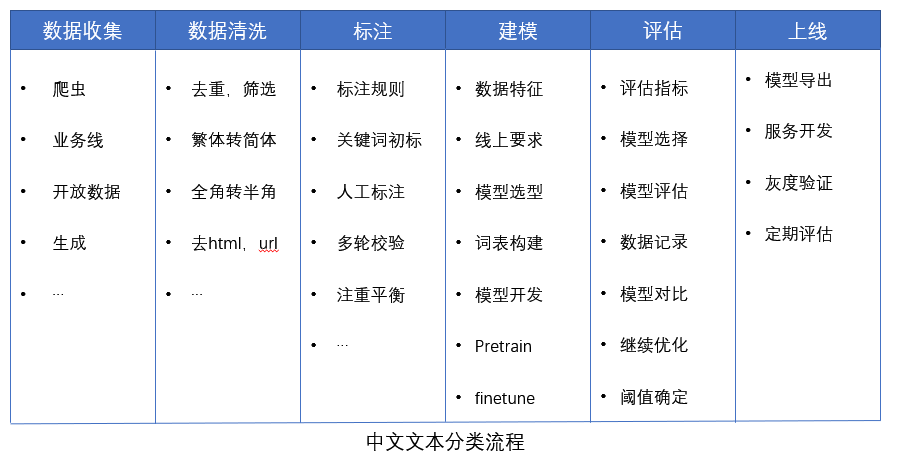
目前从事的自然语言任务基本上都是属于分类性质的,到目前为止做的分类模型累计有10余个,本文主要总结从以下几个方面进行总结:
- 数据收集和清洗
- 数据标注
- 模型选择、调优和评估
- 模型上线和持续的跟踪
- 常见问题汇总
数据收集和清洗
建模数据一般会来自爬虫,业务数据,如果是打比赛,一般会提供数据,也可以按照一定规则生成一部分数据。面对不同的任务和数据,数据收集和清洗也会不同。常见注意点如下:
- 数据收集
- 你的数据要与任务定义相匹配,比如做联系方式建模,结果收集的数据全是没有联系方式的,这没法建模。
- 数据采样最好保持数据分布的一致性,不同数据源抽取的数据最好与该数据源的总量相关。
- 对不同类别的数据要注意均衡性,可一定程度上缓解建模过程中的不平衡问题。
- 数据去重
- 过多重复的数据对标注,建模和评估都会造成影响。重复数据导致无效标注量增加,评估时指标不可信。
- 去重最好放在文本清理之后来做,防止因小的噪声(如繁体和简体字,大小写,全角半角等)导致两个一样的文本被判断成不一样。可以采用hash来去重
- 数据筛选
- 干净的文本更有利于模型的学习
- 筛选主要去重一些明显的异常文本,如文本过长过短,缺乏明显特征,非中文文本等
- 可以采用关键字筛查,随机抽检,正则匹配等
- 注意数据清洗阶段,对数据的处理与最终使用模型的数据的处理过程要保持一致。
数据标注
模型最终能达到多好的性能,就得看数据标注的质量了。通过参与几次的标注管理,主要有以下注意点:
- 制定的类别之间需要互斥,不能互为包含。类别越少越好
- 标注规则制定:清晰,全面、无理解歧义,主要是对一些难以判断的句子的定义
- 对于特定的任务,需要了解适当的业务背景知识
- 多轮标注:对于有理解歧义的任务,如文本情绪,建议多标几轮,每个人对情绪的理解都不一样,之前出现两轮标注只有30%的文本是一致的。
- 人工抽检:适当的抽检是有必要的,防止标了很久后才发现标注的有问题
- 根据标注的分布,适当调整样本,避免严重的不平衡问题
- 积累一定量后,可以训练模型,然后让模型产生一些标注,进行人工判断,进入迭代循环过程
模型选择、调优和评估
建立模型的过程其实在整个算法流程中占比的时间较短,更多的是在数据清理上面。但是建立好的模型是很有调整性的。
注意以下几点:
- 模型设计
- 微创新:避免成为一个只会拿现有模型(如LSTM,TextCNN)进行调参的算法人员。好的模型能够充分的学习到数据的分布特征,因此建模需要根据业务和数据特点,选择合适的模型,或者对现有模型进行改造,才能事半功倍。
- baseline: 选择一个成熟的模型作为baseline,然后进行升级迭代。
- 增强特征:如果采用深度学习,通常是人工选择特征的,但是为模型增加一部分有用特征,能起到较好的作用,比如低俗检测,可以收集一些低俗的关键词,融入到模型,比让模型自己去学更加可靠点,效果也更好。
- 容量匹配: 模型的容量与数据量的比例不能相差太大,比如只有5w的样本数据,设计了个500w参数量的模型,明显不合理,会出现严重的过拟合或者是线上效果太差。我的经验:模型参数/样本量 在0.5-5之间要好点,可以保证模型得到充分的训练。
- NLP范式: pretrain + finetune,在海量数据量上进行预训练,然后在具体任务上用小样本进行微调。Bert出来后,这种范式效果都非常不错,值得尝试。但是效果与自己设计的模型差不多,还是选择小的模型较好
- 调优和评估
- 问题判断:调优的基础是要知道存在哪些问题,是过拟合、不收敛、偏差方差太大等等,先定位问题,不要这调调,那调调
- 可视化: 在模型训练过程中,将参数和各项指标可视化,可以方便查看和判断。
- 系统化: 掌握系统的调优理论
- 建立标准的测试集:建议是建立两个测试集,一个是用于模型训练后评估,一个是真实环境的数据集,用于验证模型真实的泛化能力。
- 要准确还是要召回: 一般根据运营的需求,通过阈值的设定来控制。一般倾向于要准确率,准确率高之后才考虑优化召回
- 检查数据: 测试完数据后,需要对测试的数据进行分析,看看哪些是错标,漏召的。有时候模型并不是错判,而是人工错判,多检查一下对改进数据质量很有帮助。
- 其它:
- 数据记录:对每次的模型改进,指标进行记录,这非常重要
- 构建持续迭代的体系,加快生产速度
- 注重模型结果的可复现,可以采用固定随机种子等改善措施
模型上线和持续的跟踪
模型开发好了,并不一定能够上线,或者效果并没有评估的那么好。
- 收集反馈: 及时主动去收集线上的反馈信息
- 定期进行评估:数据分布可能发生了变化,模型不再试用,需要定期评估模型的性能,以确实是否需要升级。特别是涉及到一些抗黑产的模型,需要不断的进行优化才行
持续更新中。。。
常见问题汇总
模型输入的长度如何设置?
一般先统计样本的长度分布,选择能够覆盖95%以上的长度即可
embedding size大小如何设置?
对于想利用embedding来计算两个token的相似度的任务,一般embedding size越大会越好,300,600, 1024都可以。对于分类任务来说,embedding size 大于128后也不会带来明显的提升。在NLP中embedding参数一般会占模型总参数90%以上,如果训练的数据量太少,embedding size 设置小点,如32、50等,可以防止过拟合,数据量大的话,可以设置稍微大点。
分词还是不分词?
一般来看,在中文中,词语具有丰富的语义信息,在建模过程中融入这些信息,一般会对模型提升有一定帮助。但也要结合具体的任务来看,比如情绪分类任务,情绪与词语有很大关系,因此做分词效果会好一点。对于与词语语义信息无关的任务,如识别文本中的联系方式,就没必要分词,之间使用char级别的效果也不会差,而且还能大幅降低参数量。
如果只采用char,模型可能需要另外学习到一些word级别的信息才行,对数据量的要求也会大点。
如何减少unk词?
可以采用wordpiece、char或者char + word作为词表。
用CNN还是RNN?
根据我的使用情况,RNN虽然慢点,但是线上整体的效果要好于CNN。具体使用谁还是得根据数据的特点,选择合适得模型。
padding采用pre还是post方式?
对于RNN的模型,采用pre padding的方式较好,性能会比post padding高的,这样RNN的模型特点有关,keras默认也是采用的这种。对于CNN和Attention相关的模型,两种方式都差不多。
模型收敛后,几个epoch的指标都差不多,应该选择哪一个?
先去除明显过拟合的epoch,一般dev的准确率比train的准确率低0-2%较好。在测试集上评估一下,选择效果最好的那个。
停用词要不要去?
如果采用的是深度学习模型,模型是自己去选择特征,去不去都无影响。如果采用机器学习模型,最好还是去掉,减少无关特征。