为了后续在生产环境中搭建hadoop集群,现在虚拟机中搭建一个测试用的环境。
先从单台namenode环境搭建入手,后续将搭建Hadoop高可用集群
安装环境
Centos版本:CentOS Linux release 7.3.1611 (Core)
jdk:java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64
hadoop版本:hadoop2.7.3
测试环境在Virtual box中进行
虚拟机配置
Master1:192.168.31.111
Master2:192.168.31.138
Slave1:192.168.31.137
Slave2:192.168.31.162
slave3:192.168.31.102
为了安置配置的方便,关防所有机子的防火墙
配置主机名
每台机子配上主机名(master1,master2,slave1,slave2,slave3)
1
2
3
4
5
6
| //这种方式只能临时生效,机器重启后失效
sudo vim /etc/sysconfig/network
HOSTNAME=master1
sudo hostname master1
//永久生效
sudo vim /etc/hostname
|
配置hosts文件
需要在每台机器上增加其它机器的ip列表

建立hadoop运行帐号
后续的行为都在hadoop用户下操作
1
2
3
4
5
6
7
8
| adduser hadoop
chown hadoop /home/hadoop
passwd hadoop
给hadoop加权限
chmod -v u+w /etc/sudoers
vim /etc/sudoers
hadoop ALL = (ALL)ALL
chmod -v u-w /etc/sudoers
|
配置ssh免密钥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| master:
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
然后复制到其他的slave节点中
scp ~/.ssh/authorized_keys hadoop@slave1:~/
scp ~/.ssh/authorized_keys hadoop@slave2:~/
scp ~/.ssh/authorized_keys hadoop@slave3:~/
在各个slave节点上分别执行:
在终端生成密钥,命令如下(一路点击回车生成密钥)
ssh-keygen -t rsa
将 authorized_keys 文件移动到.ssh 目录
mv authorized_keys ~/.ssh/
修改 authorized_keys 文件的权限,命令如下
cd ~/.ssh
chmod 600 authorized_keys
|
需保证两台master之间能够互相登陆,各个master能够登陆各个slave
然后在master上测试能否免密码登录各个slave
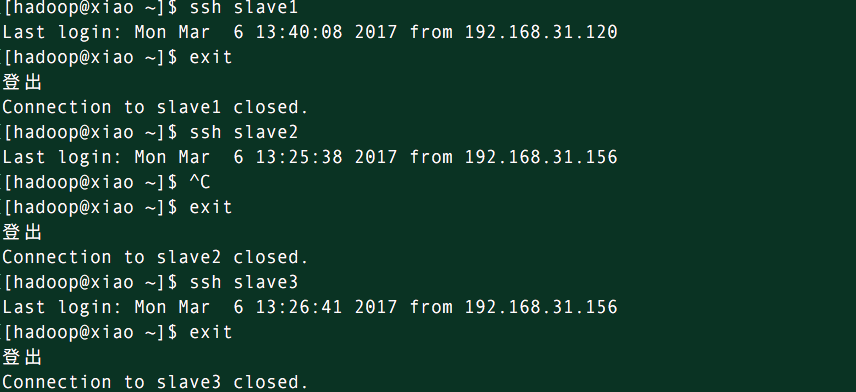
tips:
DN之间是否需要配置ssh免密钥:
datanode之间是要通信的,但不用ssh登录,只是通过socket进行通信。
Hadoop配置部署
以下先在master1机子上配置后,同步到slave机子,master2的机子后续配置双活才使用,现在不用管
1、下载并解压hadoop
1
2
| wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
tar -xvzf hadoop-2.7.3.tar.gz
|
2、配置JAVA_HOME
采用系统自带的OpenJDK
1
2
3
4
| vim /home/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre
|
3、配置 core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
</configuration>
|
4、 配置文件系统 hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| <configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master1:9001</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
</configuration>
|
5、配置yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
|
6、配置mapred-site.xml
1
2
| cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
|
配置
1
2
3
4
5
6
7
8
9
10
11
12
| <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
|
6、修改slaves文件
加入slave的列表
7、复制到从节点
将配置好的文件复制到slave中
1
2
3
| scp -r hadoop-2.7.3 hadoop@slave1:~/
scp -r hadoop-2.7.3 hadoop@slave2:~/
scp -r hadoop-2.7.3 hadoop@slave3:~/
|
启动 Hadoop 集群
1、配置 Hadoop 启动的系统环境变量(可不做)
1
2
3
4
5
6
7
| vim ~/.bash_profile
在末尾追加
#HADOOP
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使配置生效
source ~/.bash_profile
|
2、创建数据目录
在每台机子上创建
1
2
3
4
5
6
| cd ~
mkdir dfs
mkdir tmp
cd dfs
mkdir name
mkdir data
|
3、格式化文件系统
在master1机器上进行格式化,其它slave机子不需要
没有出现 Exception/Error,则表示格式化成功,不要重复的格式化,会出现问题
4、启动
1
2
3
4
| sbin/start-dfs.sh
sbin/start-yarn.sh
或者执行
start-all.sh
|
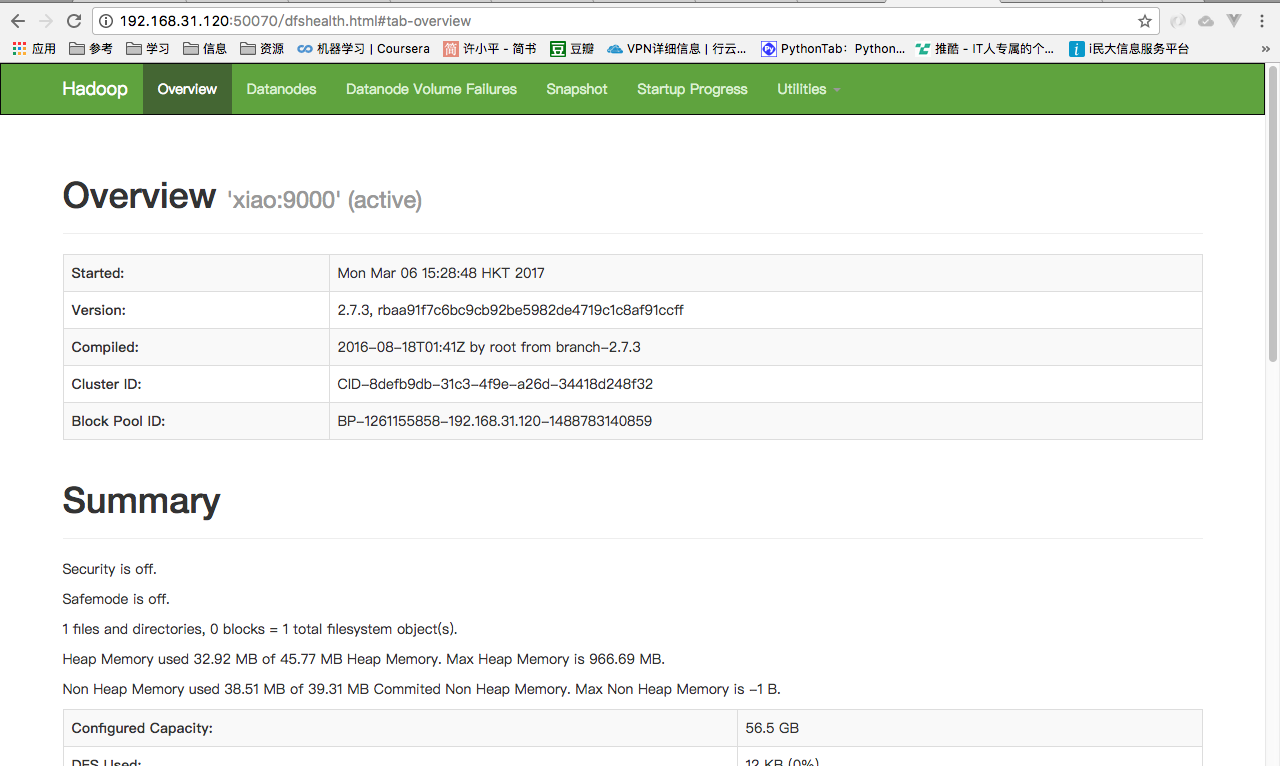
验证
1、web页面查看
http://master1:50070

http://master1:8088/cluster
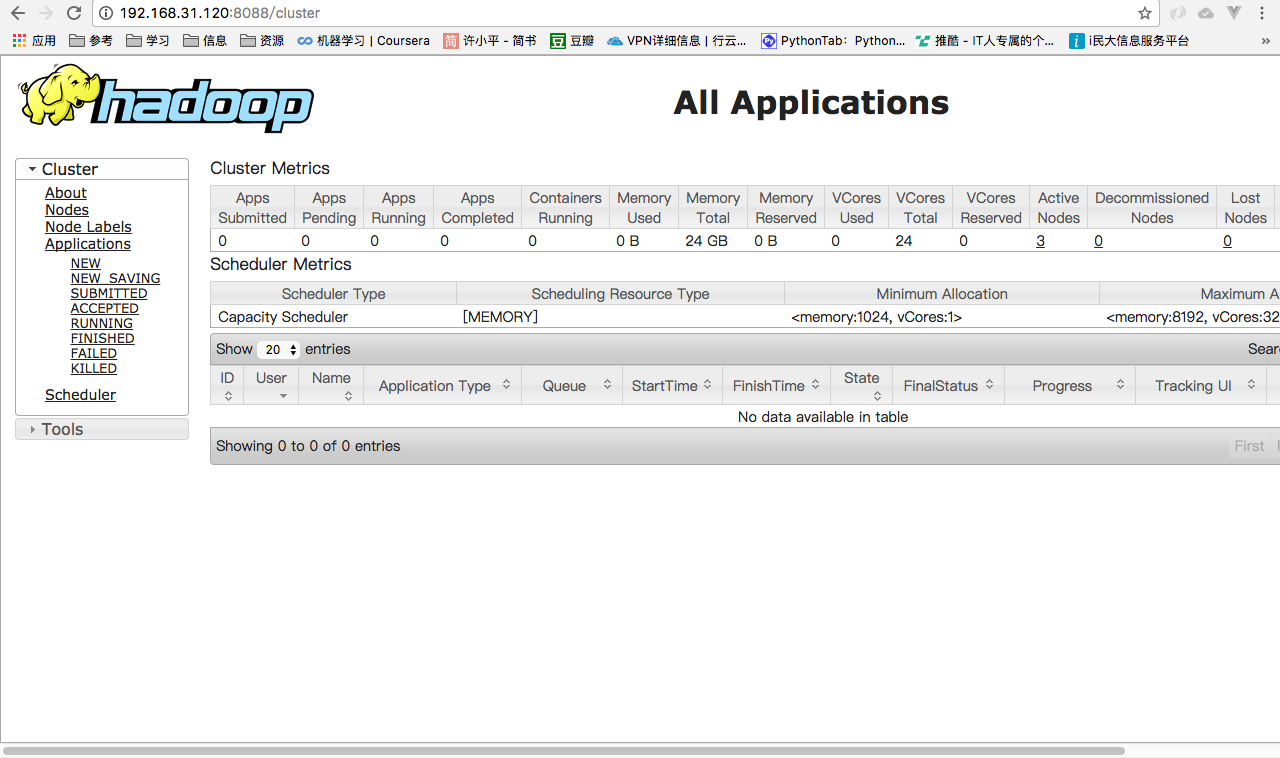
2、运行 PI 实例检查集群是否成功
1
| hadoop jar ~/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
|


出现以下问题(主机名没有配置对)
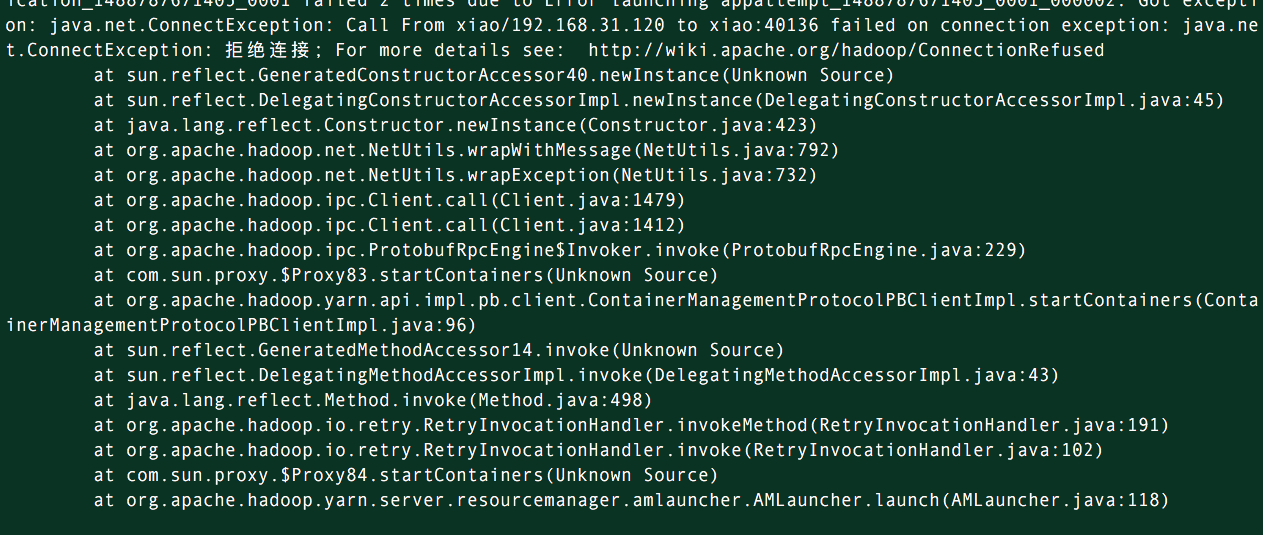
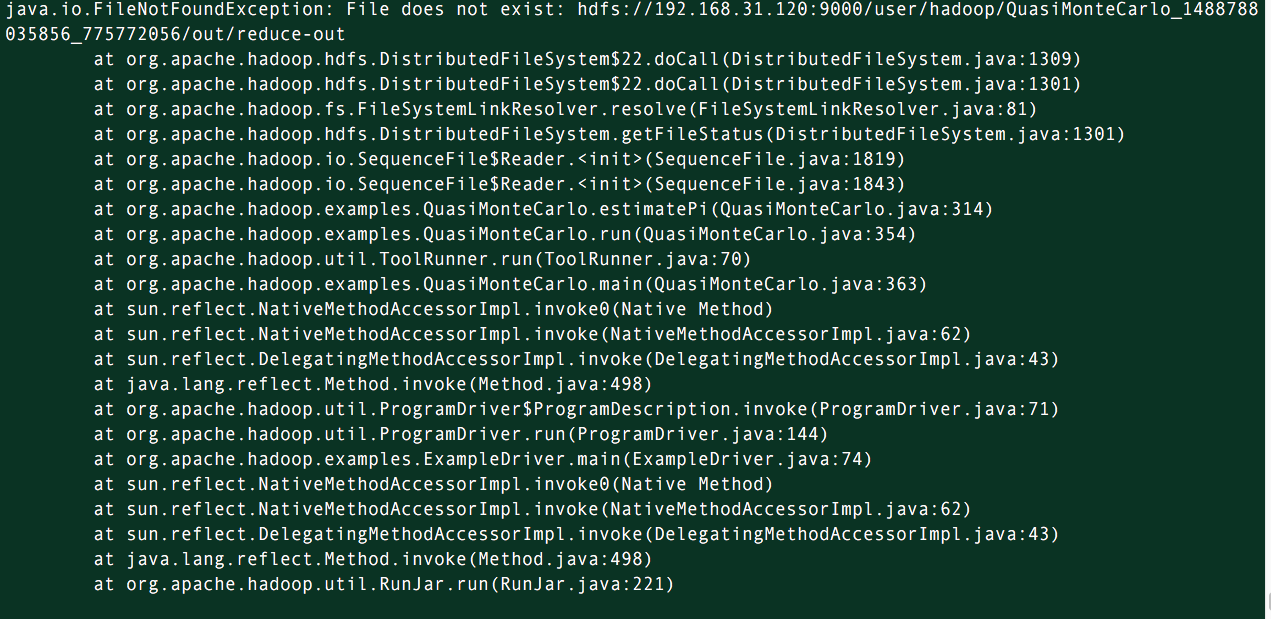
检查方法:
1、检查网络,防火墙是否有问题,需关闭所有的防火墙
2、查看配置ssh免密钥登录是否有问题
运行出错,子节点暂没互通,但是没有影响最终结果

安装过程中出现的问题
1、宿主机卡死
出现场景:
1、对虚拟机进行格式化的时候,window机器挂了
2、跑mapreduce时,window机器挂了
原因:
虚拟机的设置不对,CPU,磁盘设置过大
解决方法
设置成内存1G,硬盘固定8G
2、只启动了一个实例
原因:
一般情况下,出现这个问题的原因是namenode和datanode的clusterID不一致。namenode每次格式化时,会更新clusterID,但是datanode只会在首次格式化时确定,因此就造成不一致现象。期间尝试过重新格式化磁盘,但中途终止,导致出现此问题
解决方法(两种)
1、修改datanode里VERSION文件的clusterID与namenode的clusterID一致,重新执行start-dfs.sh
2、删除生成的节点hdfs的信息,然后重新格式化